

Solve Your Toughest Cases — FAST!

Snapshot is a cutting-edge forensic DNA analysis service that provides a variety of tools for solving hard cases quickly:
Genetic Genealogy: Identify a subject by searching for relatives in public databases and building family trees. DNA Phenotyping: Predict physical appearance and ancestry of an unknown person from their DNA. Kinship Inference: Determine kinship between DNA samples out to six degrees of relatedness.Snapshot is ideal for generating investigative leads, narrowing suspect lists, and solving human remains cases, without wasting time and money chasing false leads.
Get Started
Starting with extracted DNA or biological evidence from your case, we will predict the unknown person's ancestry and pigmentation, then perform a genetic genealogy screening to determine if such analysis would be helpful. If more information is needed, we can optionally produce a detailed phenotyping report and composite sketch and/or perform kinship analysis to advance the investigation. Armed with this scientifically objective information, you can conduct your investigation more efficiently and close cases more quickly.
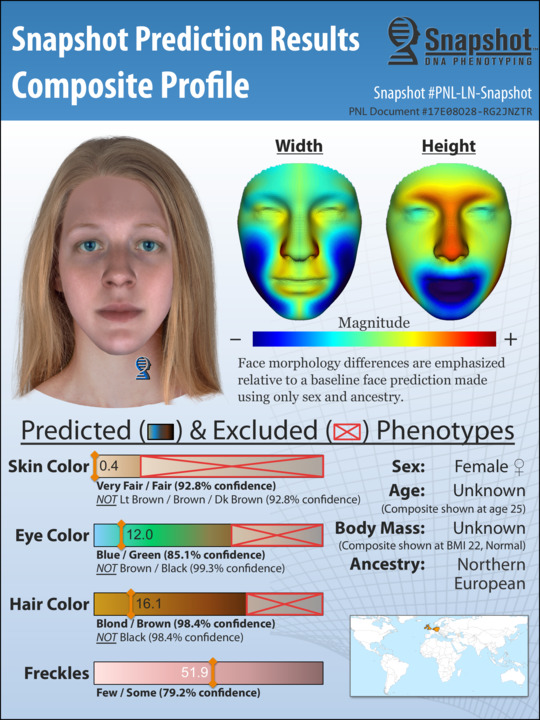

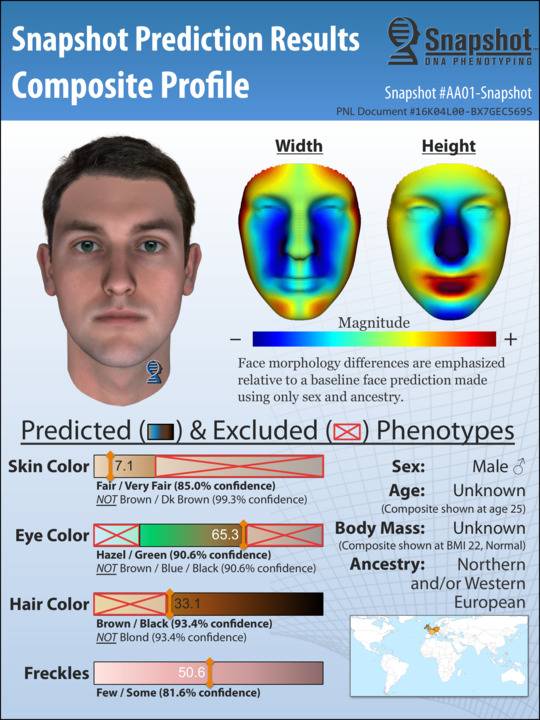

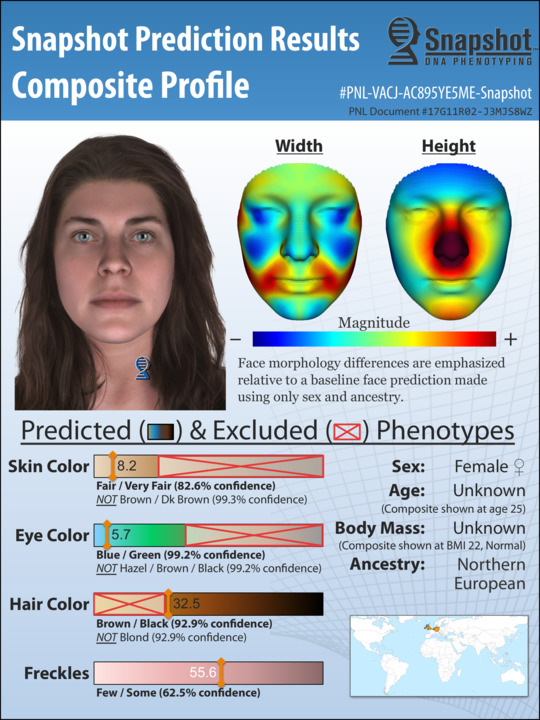

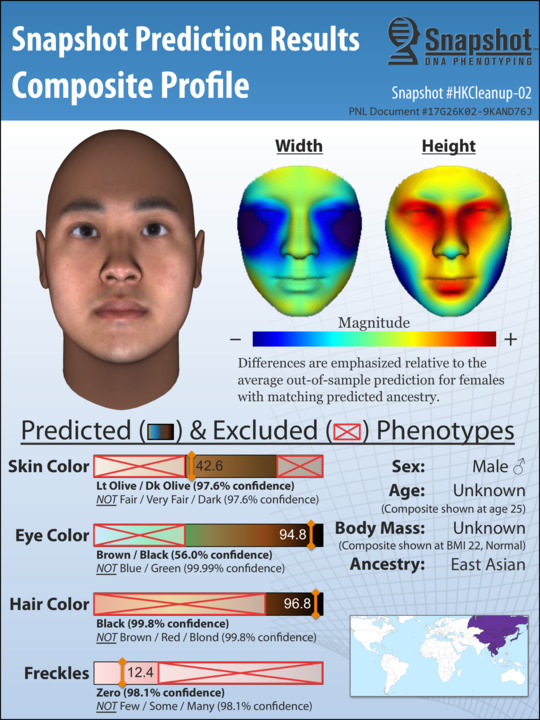

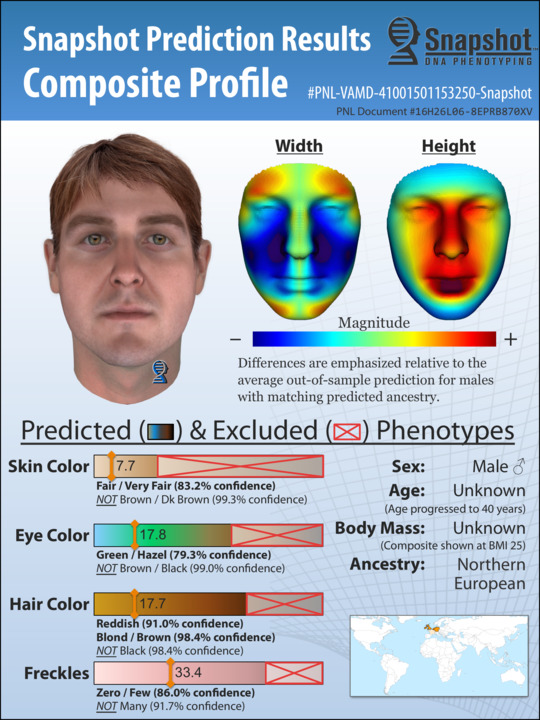

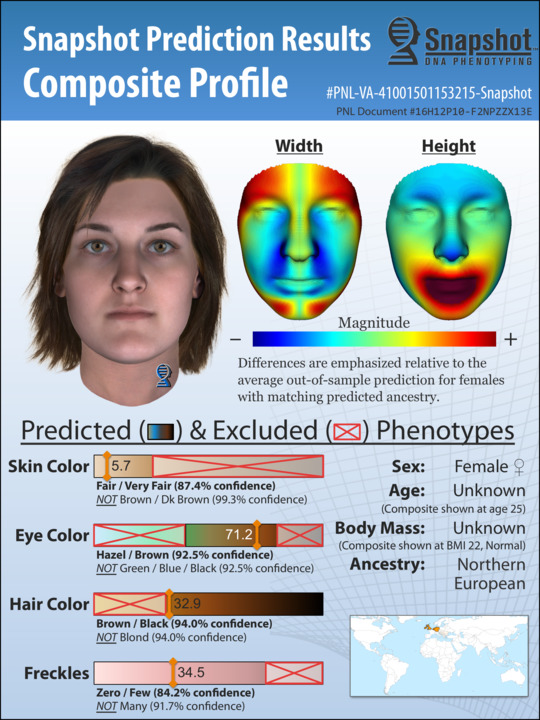



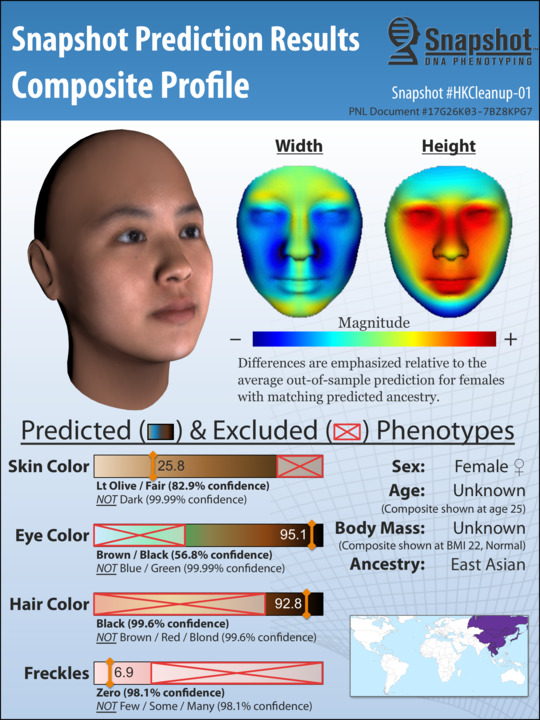

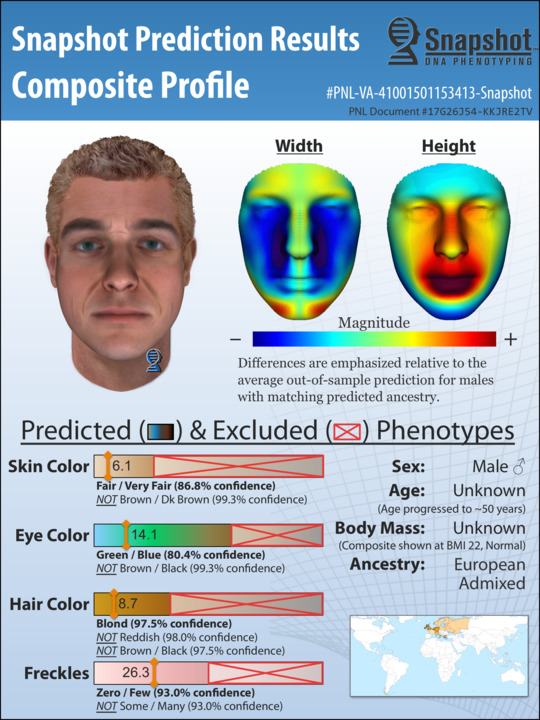

It cuts away a lot of work and effort that a lot of time in homicide investigations goes nowhere.”
generated hundreds of tips from the public. It's been very productive for us.”
hundreds and hundreds of cases that we could use this technology on.”
has led us to this type of composite.”
We've received over 100 new tips since releasing the Snapshot composites to the public.”
to the one person [of interest]. I'm sure it will start closing cold cases rapidly.”
I would be pleased to be a reference for Canadian law enforcement.”
that instead of letters and numbers, it can turn DNA into a face.”
I found Parabon to be extraordinarily responsive to the needs of law enforcement.”
yet another tool to cultivate quality forensic intelligence.”
recommend Snapshot for any investigation that involves unmatched DNA.”
that case, bringing it back to life. [Snapshot] allows you to focus your investigation.”
composite. I think this is definitely going to help.”
investigation and will prove to be an invaluable tool for investigators.”
suspect photograph] side by side, it's jaw-dropping.”
already looking to use it on at least two other cases.”
over 100 tips come in through our Ziegert tip-line... Some have been significant.”
'No match' no longer means 'no case'.”
training session that we held. I was very impressed!”
bone structure was spot on.”
will help solve more cases than you can imagine.”
composite we could share with the community. They were great partners!”
murder suspect]. It cost $4,000. And, that's probably the best $4,000 this county has ever spent.”
now, finally, with this brand new technology [Snapshot], I have eyes on that person [the perpetrator].”
significantly reduced the amount of work required to make those eliminations.”
so much time and money [and] solved this case a long, long time ago.”
leads and narrow the focus of [our] investigation to specific characteristics of the suspect.”
the perpetrator than we had before the analysis.”
much better ability to see what the person looks like.”
whole investigation and will move this case in a new direction.”
skeletal remains]. We can't say enough good things about Parabon NanoLabs.”
finding out [basic traits] will almost immediately eliminate a number of individuals who were persons of interest.”
cold cases that were previously at a standstill.”
unknown suspect from a DNA source is an invaluable tool for investigators.”
Snapshot provides a glimpse into what was previously unknown.”
after receiving Parabon's analysis, that we were able to get a hit on this suspect.”
together to answering all our questions, and they did it very quickly.”
for elimination purposes if for no other reason.”
led us to NY where we were able to attain his DNA, which matched the blood at the crime scene and led to his arrest.”
it gave us criteria with which we could exclude and include people.”
that was contracted by the APD... all contributed to the resolution of this investigation.”
driver's license photograph is quite striking.”
Snapshot's data takes imagery to a whole new level; with Snapshot, we can focus resources more precisely.”
I'm so grateful we could use it in this case.”
and [the suspect's] booking photo was uncanny.”
in your cases, you are missing critical information for your investigation.”
helped us identify a viable DNA sample and delivered an invaluable description of our perpetrator.”
it corroborates and coalesces our victim accounts of the perpetrator.”
Genealogy
Genealogy Is
Snapshot Genetic Genealogy
Genetic Genealogy (GG) is the combination of genetic analysis with traditional historical and genealogical research to study family history. For forensic investigations, it can be used to identify remains by tying the DNA to a family with a missing person or to point to the likely identity of a perpetrator.

By comparing a DNA sample to a database of DNA from volunteer participants, it is possible to determine whether there are any relatives of the DNA sample in the database and how closely related they are (see Snapshot Kinship Inference for more details). This information can then be cross-referenced with other data sources used in traditional genealogical research, such as census records, vital records, obituaries and newspaper archives.
Why Use Genetic Genealogy?
Genetic genealogy gives you a powerful new tool to generate leads on unknown subjects. When a genetic genealogy search yields useful related matches to an unknown DNA sample, it can narrow down a suspect list to a region, a family, or even an individual. Paired with Snapshot DNA Phenotyping to further reduce the list of possible matches, there is no more powerful identification method besides a direct DNA comparison. Identity can then be confirmed using traditional STR analysis.

How Does This Technique Differ From Familial Searches in the CODIS Database?
Our genetic genealogy service is somewhat like familial search, but it differs in three very important ways: (1) we only search public genetic genealogy databases, not government-owned criminal (STR profile) databases, such as CODIS; (2) because the DNA SNP profiles we generate contain vastly more information than traditional STR profiles, genetic relatedness can be detected at a far greater distance (see Snapshot Kinship Inference); and (3) because genetic genealogy matches can be cross-referenced by name with traditional genealogy sources, such as Ancestry.com, existing family trees can be used to expedite tree-building and case-solving. This technology and our innovative techniques combine to create a groundbreaking system for forensic human identification.
Genealogy Works
How Genetic Genealogy Works
Genetic genealogy uses autosomal DNA (atDNA) single nucleotide polymorphisms (SNPs) to determine how closely related two individuals are. Unlike other genetic markers, such as mitochondrial DNA or Y chromosome DNA, atDNA is inherited from all ancestral lines and passed on by both males and females and thus can be used to compare any two individuals, regardless of how they are related. However, atDNA SNPs are more difficult to obtain from forensic samples, which is why Parabon has created an optimized laboratory protocol to ensure high-quality results even from small, degraded DNA samples.
The standard atDNA metric used by genetic genealogists is the amount of DNA that two people are likely to have inherited from a recent common ancestor. This can be estimated by looking for long stretches of identical DNA. While alleles can easily be shared by chance at one or a few SNPs, it is highly unlikely for two unrelated people to share a long stretch of DNA. Therefore, only segments above a certain length are counted. The length of these shared segments is measured in centimorgans (cM), a measure of genetic distance, and the total number of cM shared across all chromosomes can be used to determine approximately how closely related two people are. The figure below shows how shared segments of DNA on a single chromosome are broken up with each generation, leading to shorter shared segments for more distant relatives. Using a public genetic genealogy database, DNA from an unknown person can be compared to roughly 1 million other people to see whether any of them are related.
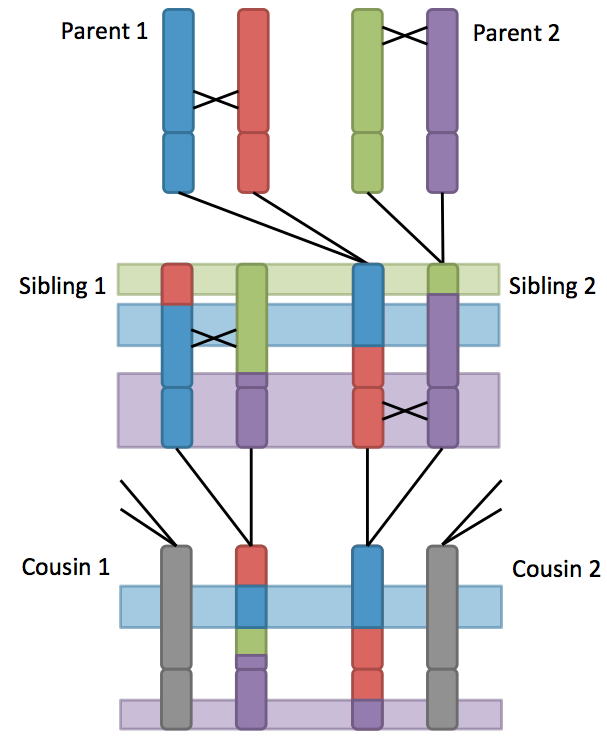
DNA database matches serve as clues on which traditional genealogy methods can build, starting with building the matches' family trees using a wide variety of information sources. During the tree building process, the genetic genealogist searched for common ancestors who appear across multiple family trees of the matches. Ideally, marriages between the descendants of the identified common ancestors are discovered. Then descendancy research is employed to search for descendants at the intersection of these common ancestors who were born at a time that is consistent with the subject's estimated age range. The goal of this search is to narrow down the possible individuals to a set of names, a family, or even an individual.
Depending on the amount of information available from the matches, genetic genealogy can produce a wide range of leads. In all cases that proceed to analysis, genetic genealogy will significantly narrow the scope of possible identities for the person-of-interest. In some cases, the identity will be narrowed to descendants of a particular ancestor or from a particular region. In others, our analysts can produce the name and address of the person-of-interest. In all cases, identity must be confirmed through traditional forensic DNA matching.
Genetic Genealogy
Use Cases
Genetic Genealogy Use Cases
Genetic genealogy has traditionally been used to discover new relatives and build a full family tree. However, it can also be used to discover the identity of an unknown individual by using DNA to identify relatives and then using genealogy research to build family trees and deduce who the unknown individual could be. These techniques have primarily been used to discover the family history of adopted individuals, but they apply equally as well to forensic applications. Genetic genealogy has been used to identify victims' remains, as well as suspects, in a number of high-profile cases.
Because genetic genealogy uses the same type of data generated for Snapshot DNA Phenotyping and Snapshot Kinship, the analysis can quickly be performed on existing cases, and new cases have a wide array of options for generating new leads from a single DNA sample.

![National Geographic Magazine Cover Story: How Science is Putting a New Face on Crime Solving [SOLVED]](/img/National-Geographic-Title.png)

Phenotyping
Phenotyping Is
The Snapshot DNA Phenotyping Service
DNA Phenotyping is the prediction of physical appearance from DNA. It can be used to generate leads in cases where there are no suspects or database hits, to narrow suspect lists, and to help solve human remains cases.

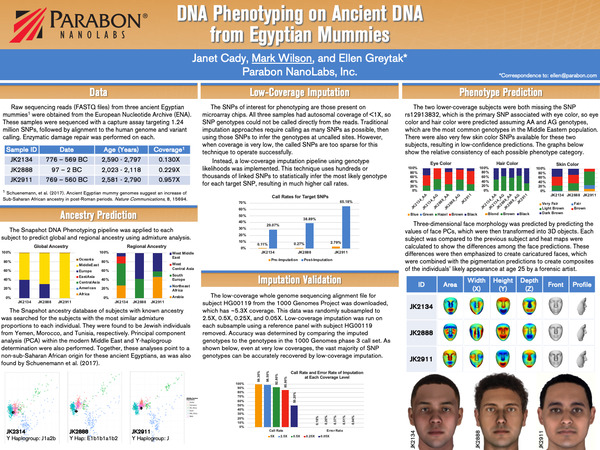
DNA carries the genetic instruction set for an individual's physical characteristics, producing the wide range of appearances among people. By determining how genetic information translates into physical appearance, it is possible to "reverse-engineer" DNA into a physical profile. Snapshot reads tens of thousands of genetic variants ("genotypes") from a DNA sample and uses this information to predict what an unknown person looks like.
Using deep data mining and advanced machine learning algorithms in a specialized bioinformatics pipeline, Parabon — with funding support from the US Department of Defense (DoD) — developed the Snapshot Forensic DNA Phenotyping System, which accurately predicts genetic ancestry, eye color, hair color, skin color, freckling, and face shape in individuals from any ethnic background, even individuals with mixed ancestry.

Because some traits are partially determined by environmental factors and not DNA alone, Snapshot trait predictions are presented with a corresponding measure of confidence, which reflects the degree to which such factors influence each particular trait. Traits, such as eye color, that are highly heritable (i.e., are not greatly affected by environmental factors) are predicted with higher accuracy and confidence than those that have lower heritability; these differences are shown in the confidence metrics that accompany each Snapshot trait prediction.
Phenotyping Works
How DNA Phenotyping Works
Whereas traditional DNA forensics matches STRs from a sample to a known suspect or a database, DNA phenotyping can generate new leads about an individual, even if they have not previously been identified in a database. DNA phenotyping takes advantage of modern SNP technology to read the parts of the genome that actually code for the differences between people.
The Snapshot DNA Phenotyping System translates SNP information from an unknown individual's DNA sample into predictions of ancestry and physical appearance traits, such as skin color, hair color, eye color, freckling, and even face morphology. Each phenotype prediction is made with a measure of confidence, including those that can be excluded with high confidence.
SNP Technology
Recent advances in genomic technology have made it practical and affordable to read the sequence of millions of pieces of DNA from a small quantity of sample. This data captures a large proportion of the genomic variation between people and thus contains much of the genetic blueprint that differentiates people's appearance. These SNP genotypes can then be paired with phenotypes from thousands of subjects to create a genotype-and-phenotype (GaP) dataset for analysis.
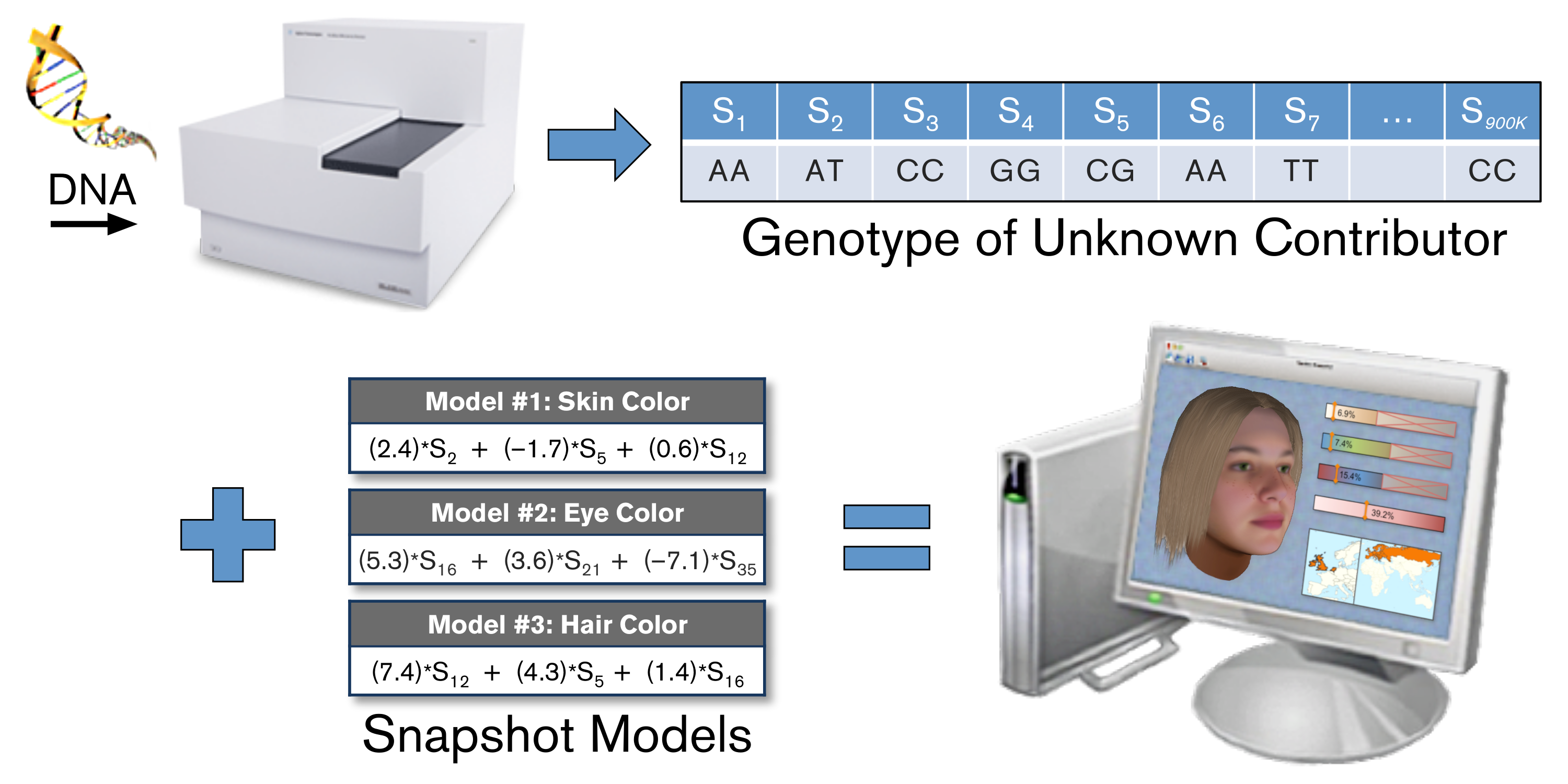
Using genomic data from large populations of subjects with known phenotypes, Parabon's bioinformatics scientists have built statistical models for forensic traits, which can be used to predict the physical appearance of unknown individuals from DNA.
Data Mining
Beginning with large GaP datasets containing genetic information and measures of phenotype for thousands of subjects, Parabon's bioinformatics team performs large-scale statistical analysis on hundreds of thousands of individual SNPs and billions of SNP combinations to identify genetic markers that are associated with a trait. This mining process can take weeks of compute time running on hundreds, sometimes thousands, of computers. In the end, those SNPs with the greatest likelihood of contributing biologically to the trait's variation are selected for potential use in predictive models.
Data Modeling
In the modeling phase, Parabon's scientists use machine learning algorithms to combine the selected set of SNPs into a complex mathematical equation for the genetic architecture of the trait. A new, unknown individual's SNP data can then be plugged into this equation to produce a prediction of the trait in that individual.
Model accuracy is assessed by making predictions on new subjects with known phenotypes ("out-of-sample predictions"). By comparing predicted versus actual phenotypes, Parabon scientists are able to calculate confidence statements about new predictions and, more importantly, exclude highly unlikely traits. For example, if 99% of brown-eyed people have an eye color prediction value greater than 2, then we can have very high confidence that a prediction of 1.5 most likely did not come from a brown-eyed person.
The final models are calibrated with all available data before being installed into the Snapshot production service that is used to generate phenotype predictions for investigators.
Phenotyping
Success Stories
Snapshot Success Stories
Snapshot has been used by hundreds of law enforcement agencies around the world to help generate leads, narrow their suspect pools, and solve human remains cases, in both active and decades-old investigations.
- Featured Case Summaries: Read detailed case descriptions, including how Snapshot helped solve the following cases:
-
Just before noon on 11 September 2008, Diane Marcell returned to her home in Albuquerque, NM, to meet her daughter, Brittani Marcell, for lunch. Brittani, then 17 years old, had driven home from her nearby high school. Upon entering her home, Diane found Brittani lying on the floor, covered in blood. A male subject, unknown to Diane, was standing near Brittani holding a shovel.
Startled, he dropped the shovel, ran into... More
In the early hours of 4 Feb 2012, Troy and LaDonna French were gunned down in their home in Reidsville, NC. The couple awoke to screams from their 19-year old daughter, Whitley, who had detected the presence of a male intruder in her second floor room. As they rushed from their downstairs bedroom to aid their daughter, the intruder attempted to quiet the girl with threats at knifepoint. Failing this, he released Whitley and raced down the stairs.
After swapping his knife for the handgun in his pocket... More
On Wednesday 14 June 2017, members of the Anne Arundel County Police Department responded to a call reporting that a body had been found in the area of East Ordnance Road and East Avenue in Glen Burnie, MD. Upon arrival, officers located badly decomposed human skeletal remains that had been covered up by a tarp. The Office of the Chief Medical Examiner later determined that the decedent was a female approximately 20 years of age and that foul play was suspected in her death.
In the fall of 2017, after initial investigative efforts failed to reveal the victim's identity... More
On Wednesday 26 March 1986, Michella Welch, a petite 12-year old girl with long blond hair and glasses, went missing. She had taken her two younger sisters to Puget Park in Tacoma, Washington at about 10 a.m. and then rode her bicycle home about 11 a.m. to make lunch for them. When she returned, she chained her bike next to one of her sister's bikes, set the lunches on the table and went looking for her siblings, who had gone to a nearby business to use the restroom.
A 13-year-old classmate later told detectives he saw a man in the park that day under the Proctor Bridge who... More
On Friday 13 May 2016, the Brown County Texas Sheriff's Office (BCSO) received a missing person report for 25-year-old Rhonda Chantay Blankinship. Family members reported Blankinship had last been seen late Friday evening, walking near her home in the Tamarack Mountain/Thunderbird Bay area of Lake Brownwood. Friends, family and volunteers began a search for her while deputies followed up on possible leads into her disappearance.
Blankinship's body was found... More
Testimonials: To read about how Snapshot has helped our clients with their investigations, see:
- https://snapshot.parabon-nanolabs.com/testimonials
Published Investigations: To learn how Snapshot is being used by additional law enforcement agencies — and to read about other solved cases — please visit the published police investigation page at:
- https://snapshot.parabon-nanolabs.com/posters
Blind Evaluations: Snapshot was built by Parabon NanoLabs for the defense, security, justice, and intelligence communities with funding from the United States Defense Threat Reduction Agency. As part of the development and validation process, Snapshot was tested on thousands of out-of-sample genotypes and was shown to be extremely accurate.
To see examples of Snapshot predictions from blind evaluation studies, visit:
- https://snapshot.parabon-nanolabs.com/examples
Example of How To Use Snapshot: To learn how you can use Snapshot to narrow a suspect pool, watch:
- https://snapshot.parabon-nanolabs.com/nbc-news-video






Determination
Determination Is
Predicting Genetic Ancestry With Snapshot
Scientific analysis of human genomes from different parts of the world has shown that, on a global scale, modern humans divide genetically into seven continental populations: African, Middle Eastern, European, Central/South Asian, East Asian, Oceanian, and Native American1. These genetic divisions stem simply from the fact that these groups were isolated from one another for many generations, and thus each group has a unique genetic signature that can be used for identification. In order to determine a new subject's genetic ancestry, Parabon Snapshot analyzes tens of thousands of SNPs from a DNA sample to determine a person's percent membership in each of these global populations. Other forensic ancestry approaches assume that every individual comes from only a single population, so they can easily be confounded by admixed individuals, but Snapshot allows for contributions from multiple populations, so it can detect even low levels of admixture (<5%).
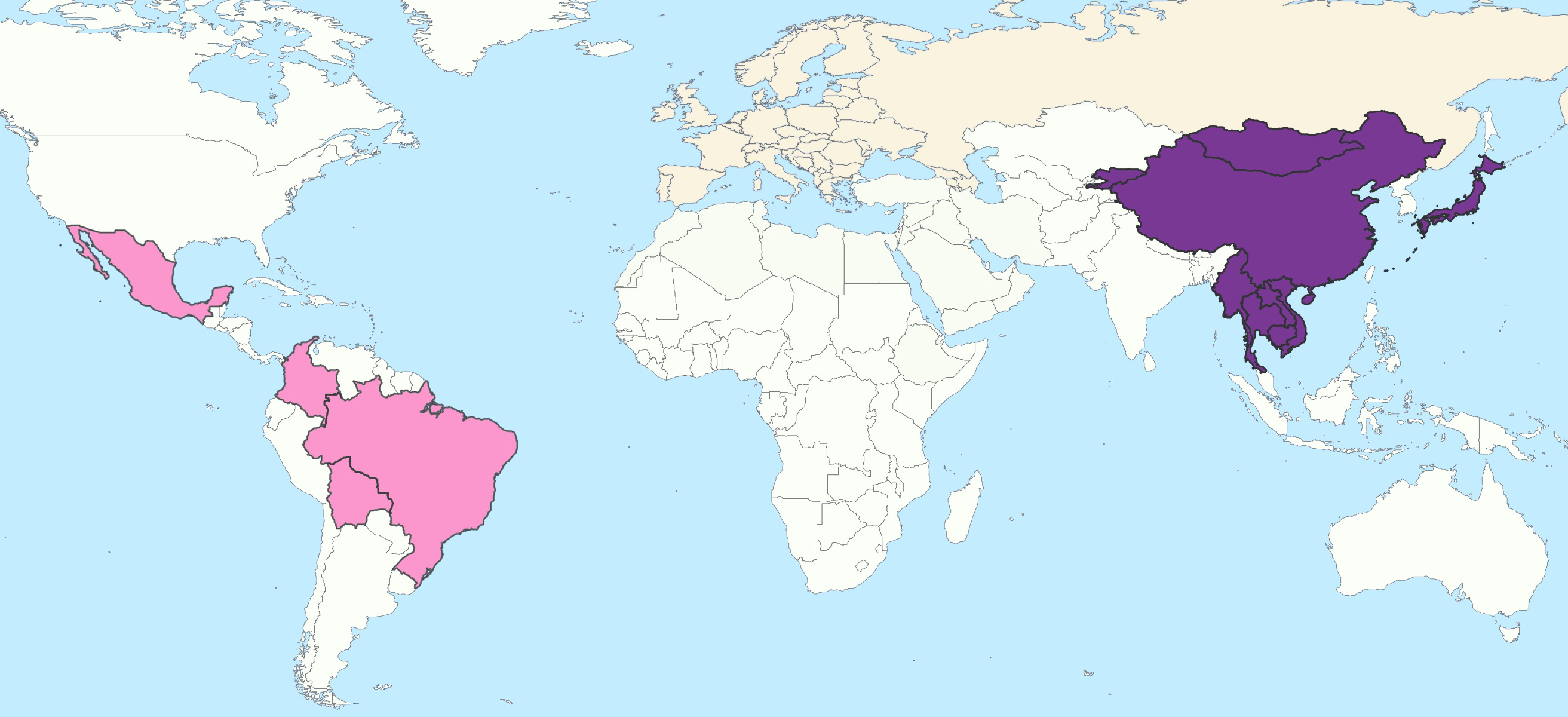
Global ancestry map showing mostly East Asian and Native/South American ancestry, with some European ancestry as well.
After global ancestry is determined, Snapshot's ancestry algorithm investigates which subpopulations (e.g., Northwest vs. Northeast Europe) an individual comes from. This analysis is robust to admixture, such that each piece of continental ancestry can be precisely localized within that continent. For example, the admixed East Asian and Latino example from the global map above was determined to have specifically Japanese, Central American, and Southwest European ancestry, as shown in the map below.

Regional ancestry map showing mostly Japanese, Southwest European, and Central American ancestry.
Using all of this information, Snapshot builds a precise profile of an individual's ethnic ancestry using only his or her DNA.
Determination Works
How Genetic Ancestry Determination Works
Parabon has built a powerful system for determining ethnic ancestry from DNA. Most other forensic ancestry systems use only a small number of SNPs and thus are limited to very coarse populations and cannot detect admixture between populations. Snapshot uses tens of thousands of SNPs across the genome to obtain very precise estimates of ancestry, even for admixed individuals. Parabon's scientists have collected data from many published scientific articles, totalling more than 9,000 individuals with clearly defined ancestry from more than 150 populations around the world, as shown in the map below.
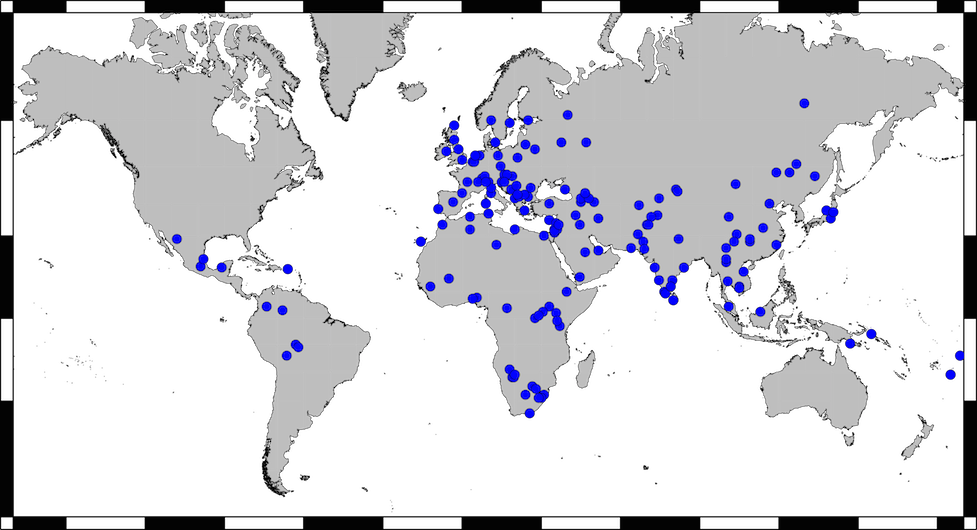
Each point represents a population from which we have obtained ancestry background data. Efforts are ongoing to increase the representation of Native American populations.
Academic research using hundreds of thousands of SNPs from across the genome has shown that human groups generally divide into seven continental populations, which have been established over the past 50,000 years during the migration out of Africa. The 150 populations collected as the ancestry background can thus be divided into these seven continental groups according to their origin.
Snapshot builds on this research by mapping a new person's genome onto these established populations. Our algorithm calculates how similar the new individual's DNA is to each of the background populations, determining which population(s) the person comes from. This allows for contributions from multiple groups, so even small amounts of admixture (<5%) can be detected.
Snapshot takes a similar approach to identifying within-continental (regional) ancestry, although the local populations were identified through empirical analysis performed by our bioinformatics team. Each piece of continental ancestry is partitioned according to its regional ancestry (e.g., if an individual is 50% European and 50% East Asian, the precise origin of each of those pieces will be determined). The person's genome is also plotted against all of the known individuals in each region to show visually where he or she falls.
Below is an example plot for an individual who was determined to be 50% East Asian and 50% Latino. Latino ancestry is a mixture of European and Native American ancestry, so these groups are shown as well.
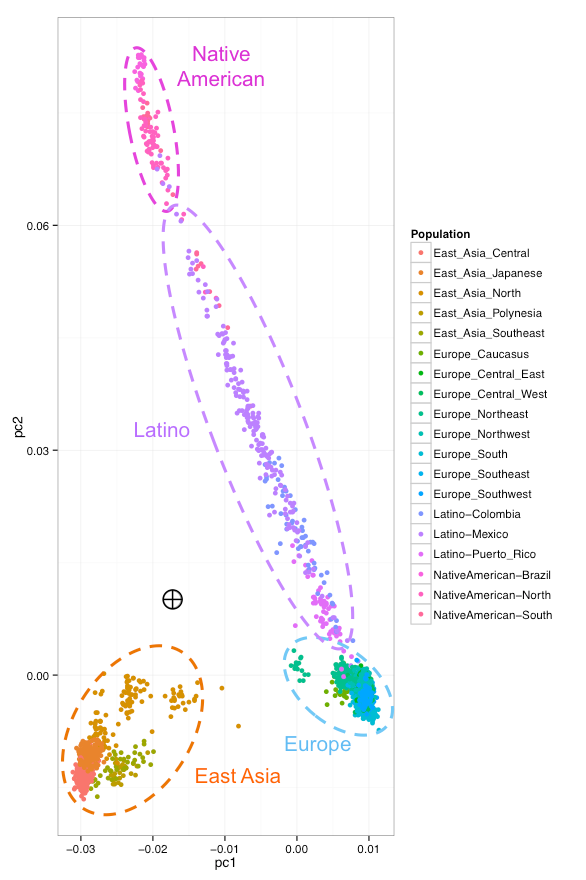
Ancestry clustering diagram; this individual is half Japanese and half Latino.
Determination
Use Cases
Ancestry Determination Use Cases
Ethnic ancestry is one of the most informative traits that can be predicted from DNA. In an ancestry analysis, Snapshot will determine an individual's precise genetic origins, as well as whether there is any evidence of admixture (contribution from multiple populations). This information can be used to help identify remains or to significantly focus an investigation by excluding a wide range of possible suspects or even pointing to a very small group.


Inference
Inference Is
Snapshot Kinship Inference™
Snapshot Kinship Inference provides highly accurate inferences about the familial relationship between two people based on their DNA, even if they are distantly related. Unlike traditional forensic DNA methods, which are extremely limited in their ability to determine kinship (see tan region in the figure below), Snapshot can detect relatedness out to 9th-degree relatives (fourth cousins). This powerful forensic analysis tool gives investigators valuable, previously unobtainable information about the DNA samples found at a crime scene — information that can save time and money and lead to more solved cases.
Thanks to the massive amount of information contained in genome-wide SNP data, using DNA extracted from two biological samples, it is possible to precisely calculate the degree of relatedness between the contributors, even if the relationship is very distant.
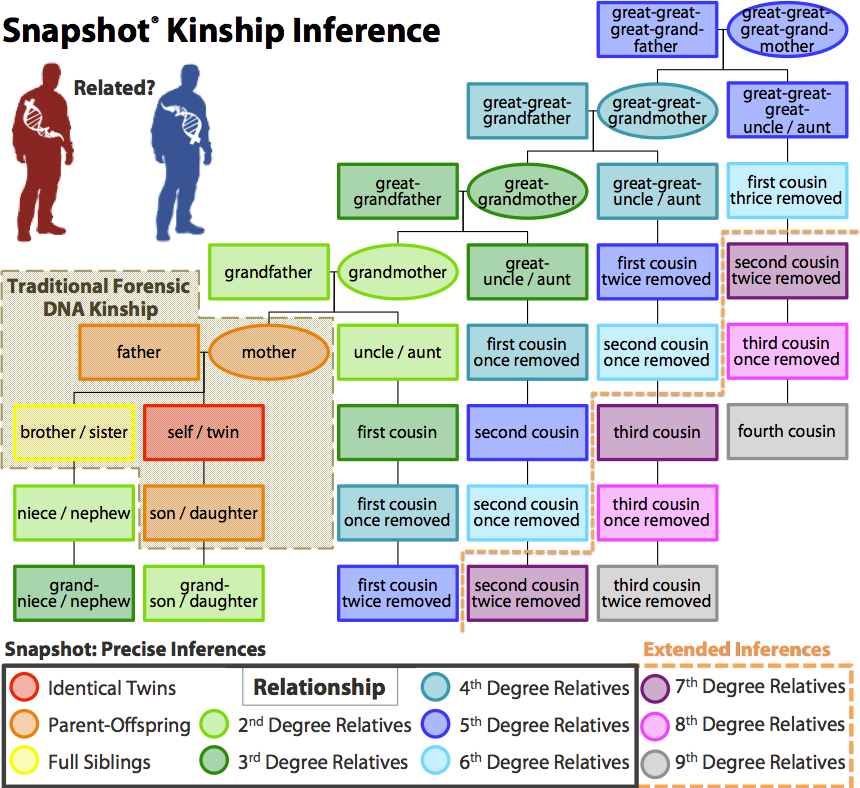
Built with advanced machine learning algorithms, the Snapshot kinship model can distinguish up to 9th-degree relatives (fourth cousins) from unrelated pairs.
Traditional STR-based kinship analysis is limited to distinguishing parent/offspring relationships, often yielding inconclusive results for siblings or other second-degree relatives. Snapshot's kinship model, on the other hand, uses hundreds of thousands of SNPs to detect relatedness out to 9th-degree relationships — e.g., fourth cousins. Moreover, the precise degree of the relationship can be determined out to 6th-degree relatives (second cousins once removed) while minimizing false positives — i.e., unrelated pairs mistakenly inferred to be related.
Inference Works
How Snapshot Kinship Inference Works
Traditional autosomal kinship analysis uses fewer than 20 short tandem repeat (STR) loci, which lack the resolution to establish relatedness beyond parent-offspring or full siblings, and is easily confounded by mutation or mistaken testing of a close relative of the true parent.1 Other forensic analyses use pieces of DNA that are directly transmitted through the maternal (mitochondrial DNA) or paternal (Y-chromosome) lines; however, these approaches are limited to a small subset of relationships and have very low resolution. For example, ~7% of unrelated Europeans share the same mitochondrial haplotype, meanting that they cannot be assigned to a specific family. MtDNA and Y-STRs can only suggest that two individuals may be related but cannot say whether that relationship is close or very distant.
Dissatisfied with these limitations, Parabon's scientists set out to develop a novel algorithm that takes advantage of the massive amount of autosomal data made available by genome-wide SNP typing to compare two genomes and determine the precise degree of relatedness between the two individuals. The result is a revolutionary new test that redefines the state-of-the-art in kinship analysis.
Parabon's kinship algorithm analyzes the similarity between two genomes and uses a machine learning model to predict the degree of relatedness of the two individuals. In thousands of out-of-sample predictions, this method has proven to be highly accurate while maintaining a very low false-positive rate (i.e., unrelated pairs are almost never mistakenly inferred to be related). This is true across subjects from a range of ethnic backgrounds, including related pairs with different ethnic backgrounds. Absolute accuracy is >90% out to 3rd-degree relatives (first cousins), and Snapshot can distinguish 6th-degree relatives (e.g., second cousins once removed) from unrelated pairs with greater than 98% accuracy.
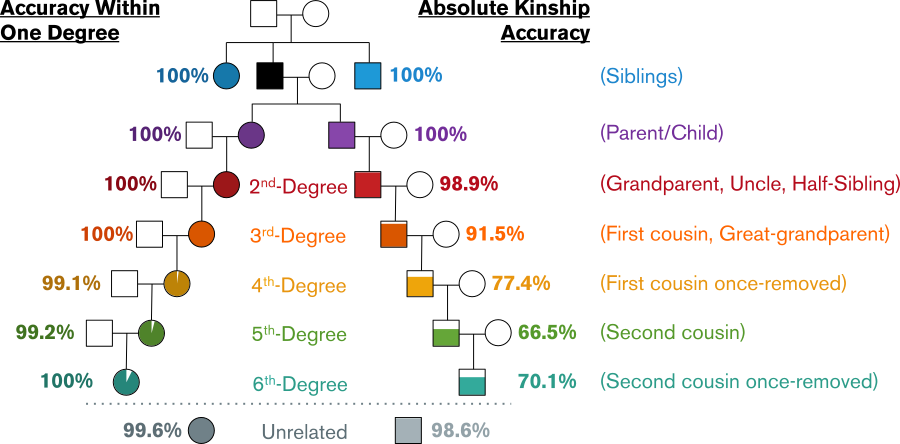
Snapshot Kinship Accuracy, measured as the frequency of correct predictions of the exact degree of relatedness (absolute accuracy) and the frequency of predictions within one degree of actual relatedness (n = 3,654 relationships).
As shown in the figure above, even when Snapshot incorrectly infers the degree of relatedness between two individuals, it is almost always correct within one degree. For example, Snapshot may occasionally incorrectly predict a 4th-degree relationship to be a 5th-degree relationship, but it rarely makes the mistake of predicting a 4th-degree relationship to be a 6th-degree relationship. With this level of accuracy, you can be confident that the inferences provided by Snapshot are reliable and actionable.
[1] Chakraborty, R., et al. (1999). The utility of short tandem repeat loci beyond human identification: implications for development of new DNA typing systems. Electrophoresis, 1682–1696.
Inference
Use Cases
How Snapshot Kinship Inference is Used
Snapshot Kinship Inference can be used to establish familial relationships between a DNA sample and previously collected DNA samples or among a set of new samples, e.g.:
- If there is a chance that the perpetrator of a crime is related to the victim, Snapshot can compare the victim's DNA to a crime scene DNA sample to determine whether they are related. With just one test, investigators and include or exclude the entire extended biological family of the victim.
- If DNA from a suspect cannot be obtained, but a consenting family member is willing to contribute a sample, Snapshot can establish whether that family member is related to a crime scene DNA sample.
- If the identity of unidentified remains is suspected, but only distant relatives are available, Snapshot can compare DNA from the remains (even bone) to that of a relative to determine whether they are related.
According to the U.S. Department of Justice (DOJ) Bureau of Justice Statistics, over 60% of all violent crimes in 2016 [the latest period for which data is available] were committed by persons known to the victim.1
Knowledge of these relationships can be used to validate claims of distant kinship, establish relationship networks within groups of interest, or identify remains when close relatives are not available, such as cold cases, mass disasters, or casualties of past conflicts.
[1] Morgan R. and Kena G., Criminal Victimization, 2016, US Department of Justice, Office of Justice Programs, Bureau of Justice Statistics, NCJ 251150, Dec 2017. https://www.bjs.gov/content/pub/pdf/cv16.pdf. Retrieved: 19 Feb 2018.
Enhancement
Enhancement Is
Forensic Art Enhancement
While DNA can reveal much about the appearance of a subject, information about features such as age, body mass index (BMI) or the presence of facial hair are not available within an individual's genetic code. Snapshot forensic art services provide a means of incorporating such information into a Snapshot composite when it is available from non-DNA sources.

Examples of age progression and accessorization with Snapshot Forensic Art Services. By default, Snapshot produces composites from DNA at 25 years of age (A). Composite (A) shown after age progression to age 50 years (B); with the addition of a light beard (C); after further age progression to age 75 years with reading glasses (D); and with a full beard (E)
Our Forensic Art Department — under the direction of Thom Shaw, who is certified by the International Association for Identification (IAI) in the discipline of forensic art — offers age progression, BMI alteration, and accessorization services, which may include the addition of facial hair, eyeglasses, piercings, etc. We can also create composite sketches from eyewitness accounts and combine them with traditional Snapshot composites; in this way, corroborating the witness account or adding objective phenotype information to help produce the most accurate composite possible.

Composite (A) shown after age progression to 50 years old, including a beard (B) as compared to the actual subject (C)
In cases involving unidentified remains where a skull or partial skull is available, our forensic artists are also trained to perform digital facial reconstruction, using bone structure to enhance or give nuance to a Snapshot composite.
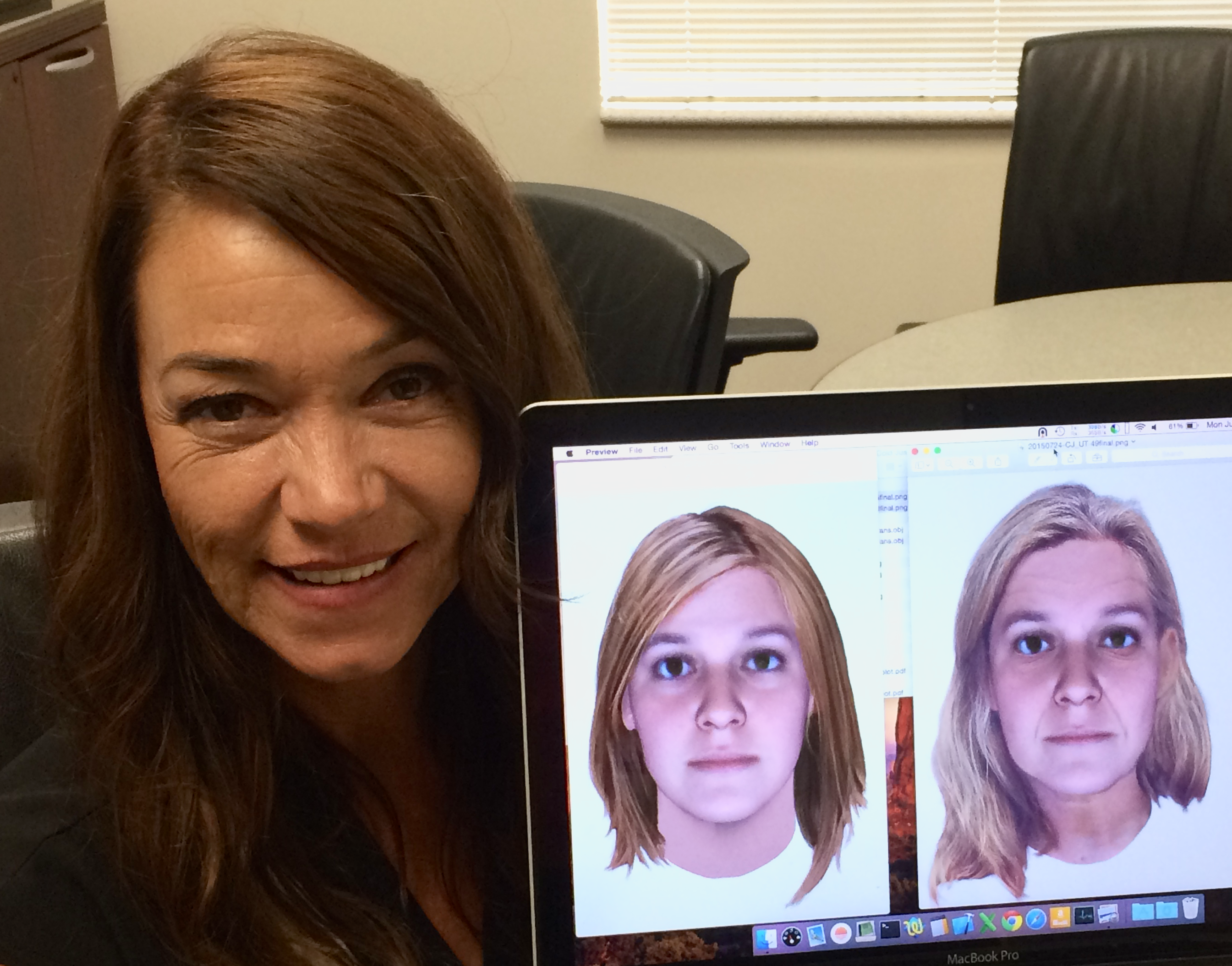
Snapshot predictions for Yolanda McClary, investigator for TV's "Cold
Justice",
shown at age 25 and age progressed to 49 years old
Collectively, these forensic art services perfectly complement what Snapshot can provide from DNA alone and together they represent a revolution in how DNA can be used in an investigation.
Enhancement Works
How Forensic Art Enhancement Works
Forensic artists are artists with special training to address forensic challenges. They have an expert understanding of the human face and how the effects of aging and body mass index (BMI) change appearance. Those trained in facial reconstruction learn how to infer the most likely distribution of muscle and soft tissue from a skull. Forensic artists who create composite sketches from eyewitness accounts are trained to conduct cognitive interviews, so as to get the most accurate portrayal from a witness' memory.
Like many domains, forensic artists are beginning to rely heavily on modern software applications to facilitate their work. Sketches formerly performed with pencil and pad can now be drawn digitally. As well, facial reconstructions once performed with clay sculpture can also be digitally sculpted. In the right hands, graphics software programs can ease the task of adding or subtracting hair, scars, and other accessories. In all cases, great skill and specialized training is still required, but the work can be more efficient and realistic thanks to these tools.
Enhancement
Use Cases
Forensic Art Enhancement Use Cases
There are a number of use cases for which forensic art can be used.Age Progression or Regression
Because age is not genetically encoded, Snapshot predicts subjects at 25 years of age by default. When investigators have reason to believe a person of interest is younger or older, our artists can adjust a composite accordingly, based on standard aging principles.

Examples of age progression with Snapshot Forensic Art Services: the predicted composite at 25 years old (A); shown after age progression to age 50 years (B); and after further age progression to 75 years of age
Composites Based on Eyewitness Account
Our forensic artists are trained to conduct cognitive interviews and produce composites solely from an eyewitness account. The interview and composite production is conducted online with screen sharing technology, so eyewitnesses do not have to travel. When DNA is available for the same person of interest as seen by the eyewitness, Snapshot can provide a corresponding composite from "the genetic witness" perspective. Our artists can combine a composite from an eyewitness account with one produced by Snapshot to produce a single, highly accurate rendering that contains the best that both sources of information can offer.
Accessorization
In some instances, descriptive information about a subject's accessories or distinguishing features is available that can be used to enhance a Snapshot composite. For example, a surveillance camera image may be too grainy for identification, but nevertheless suggestive that a suspect has facial hair. Similarly, an eyewitness may recall a tattoo or scar, even though they were too traumatized to remember much else. In such cases, our forensic artists can accessorize a Snapshot composite to include all available descriptive information about a subject.

Examples of accessorization with Snapshot Forensic Art Services: the predicted composite at 25 years old (A); shown after age progression to age 50 years, with the addition of a light beard (B); and after further age progression to age 75 years with reading glasses and a full beard (C)
Body Mass Index (BMI) Alteration
Besides the effects of aging, changes in BMI have among the largest effects on appearance. By default, Snapshot produces composites assuming the subject has a BMI of 22, which is considered average. When information is available that suggests a subject has a lower or higher than average BMI, forensic artists can appropriately alter the BMI of a Snapshot composite.

Extreme examples of body mass index (BMI) alteration: the original prediction (A); shown with significantly less body mass (B); and again with a significantly larger amount of body mass (C)
Unidentified Remains
When unidentified human remains include a skull, our forensic artists can perform facial reconstruction, literally building up the corresponding face using knowledge of facial musculature and soft tissues. Although facial features cannot be perfectly inferred from a skull, bone structure can be immensely informative about the shape of an individual's face. Snapshot predicts exterior face morphology, but when a skull is available, a forensic artist can use it to confirm or enhance a Snapshot composite based on facial reconstruction.
Reconstruction
Reconstruction Is
Snapshot Facial Reconstruction
By combining two complementary methods of estimating appearance from skeletal evidence — DNA phenotyping and forensic facial reconstruction — the Snapshot Facial Reconstruction Service produces the most fully informed recreations of antemortem appearance ever produced from skeletal remains.
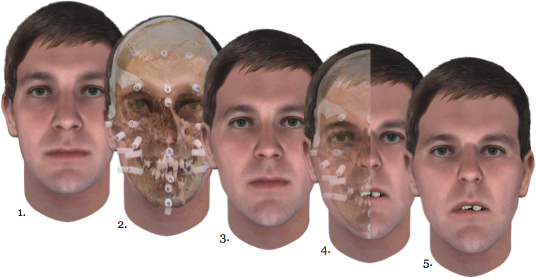
Stages of a Snapshot Facial Reconstruction: (1) a Snapshot composite produced from DNA extracted from the subject's bone; (2) Snapshot composite with skull overlay; (3) Snapshot composite after rescaling to conform to skull dimensions; (4) a cutaway image illustrating near final composite; and (5) final, blended Snapshot composite.
Reconstruction Works
How Snapshot Facial Reconstruction Works
Snapshot phenotyping algorithms are used to predict a decedent's appearance and ancestry using DNA extracted from bone. Independently, a traditional facial reconstruction is performed by a forensic artist who has been specifically trained to interpret Snapshot DNA Phenotyping results. Tissue depth markers are physically applied to the decedent's skull, based on DNA-determined ancestry and estimated body weight, to produce a prediction of face shape from cranial morphology. A final composite is then produced by digitally blending the two predictions.
Thom Shaw, an IAI-certified forensic artist at Parabon NanoLabs, performing a physical facial reconstruction and the digital adaptation of a Snapshot composite to reflect details gleaned from the victim's facial morphology.
Facial
Reconstruction
Benefits of Snapshot Facial Reconstruction
Combining DNA phenotyping and forensic facial reconstruction has several benefits over either method applied individually:
- Traditional forensic facial reconstruction often lacks ancestry and pigmentation information about a dependent, which is why they are often depicted in grayscale.
- In cases of prolonged decomposition, scavengers may remove the mandible (jawbone) from a skull. Snapshot DNA Phenotyping can provide a forensic artist with a solid prediction of jaw shape to assist with the reconstruction process.
- DNA phenotyping models are tuned to explain only normal variation in appearance, whereas skull evidence may reveal distinguishing facial features that may be difficult to predict from DNA alone.
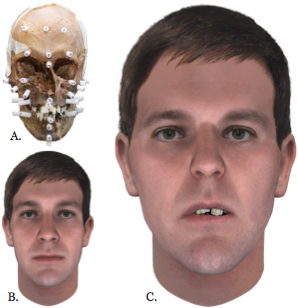
When the evidence for a case includes the victim's skull (A), it may be possible to perform forensic facial reconstruction to further enhance the Snapshot prediction (B), resulting in the final blended Snapshot composite (C).
For ordering information, please contact snapshot@parabon-nanolabs.com or call (703) 689-9689 x251